原文地址:
—— —— 本系列博客源代码是基于GlusterFS 3.4.3 版本号
1. Glusterfs简单介绍
是Scale-Out存储解决方式的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展可以支持数PB存储容量和处理数千client。GlusterFS借助TCP/IP或InfiniBandRDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
2. Glusterfs特点
2.1 扩展性和高性能
GlusterFS利用双重特性来提供几TB至数PB的高扩展存储解决方式。Scale-Out架构同意通过简单地添加资源来提高存储容量和性能,磁盘、计算和I/O资源都能够独立添加,支持10GbE和InfiniBand等快速网络互联。Gluster弹性哈希(ElasticHash)解除了GlusterFS对元数据server的需求,消除了单点故障和性能瓶颈,真正实现了并行化数据訪问。
2.2 高可用性
GlusterFS能够对文件进行自己主动复制,如镜像或多次复制,从而确保数据总是能够訪问,甚至是在硬件故障的情况下也能正常訪问。自我修复功能能够把数据恢复到正确的状态,并且修复是以增量的方式在后台运行,差点儿不会产生性能负载。GlusterFS没有设计自己的私有数据文件格式,而是採用操作系统中主流标准的磁盘文件系统(如EXT3、ZFS)来存储文件,因此数据能够使用各种标准工具进行复制和訪问。
2.3全局统一命名空间
全局统一命名空间将磁盘和内存资源聚集成一个单一的虚拟存储池,对上层用户和应用屏蔽了底层的物理硬件。存储资源能够依据须要在虚拟存储池中进行弹性扩展,比方扩容或收缩。当存储虚拟机映像时,存储的虚拟映像文件没有数量限制,成千虚拟机均通过单一挂载点进行数据共享。虚拟机I/O可在命名空间内的全部server上自己主动进行负载均衡,消除了SAN环境中常常发生的訪问热点和性能瓶颈问题。
2.4 弹性哈希算法
GlusterFS採用弹性哈希算法在存储池中定位数据,而不是採用集中式或分布式元数据server索引。在其它的Scale-Out存储系统中,元数据server一般会导致I/O性能瓶颈和单点故障问题。GlusterFS中,全部在Scale-Out存储配置中的存储系统都能够智能地定位随意数据分片,不须要查看索引或者向其它server查询。这样的设计机制全然并行化了数据訪问,实现了真正的线性性能扩展。
2.5 弹性卷管理
数据储存在逻辑卷中,逻辑卷能够从虚拟化的物理存储池进行独立逻辑划分而得到。存储server能够在线进行添加和移除,不会导致应用中断。逻辑卷能够在全部配置server中增长和缩减,能够在不同server迁移进行容量均衡,或者添加和移除系统,这些操作都可在线进行。文件系统配置更改也能够实时在线进行并应用,从而能够适应工作负载条件变化或在线性能调优。
2.6基于标准协议
Gluster存储服务支持NFS,CIFS, HTTP, FTP以及Gluster原生协议,全然与POSIX标准兼容。现有应用程序不须要作不论什么改动或使用专用API,就能够对Gluster中的数据进行訪问。这在公有云环境中部署Gluster时很实用,Gluster对云服务提供商专用API进行抽象,然后提供标准POSIX接口。
3. 模块化堆栈式架构简单介绍
GlusterFS採用模块化、堆栈式的架构,可通过灵活的配置支持高度定制化的应用环境,比方大文件存储、海量小文件存储、云存储、多传输协议应用等。每一个功能以模块形式实现,然后以积木方式进行简单的组合,就可以实现复杂的功能。比方,Replicate模块可实现RAID1,Stripe模块可实现RAID0,通过两者的组合可实现RAID10和RAID01,同一时候获得高性能和高可靠性。例如以下图所看到的:
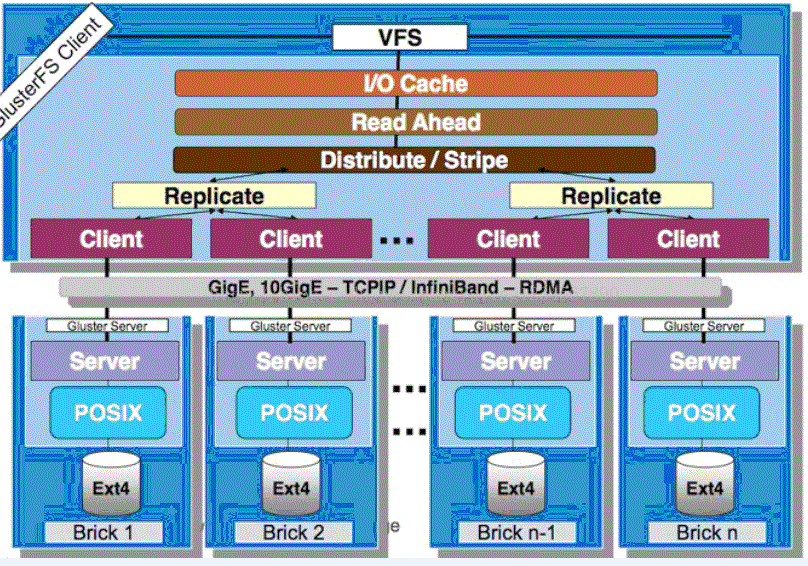
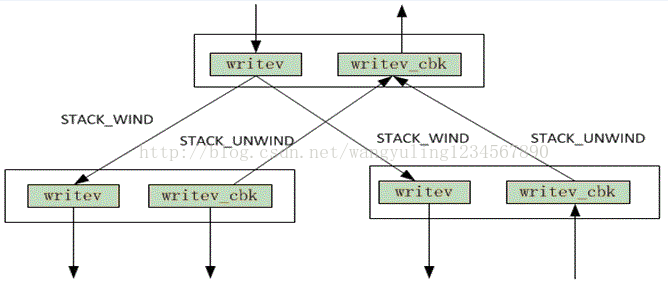
每一个功能模块就是一个Xlator,不同的xlator在初始化后形成树,每一个xlator为这棵树中的节点,glusterfs要工作,就必定会涉及到节点之间的调用。
调用主要包含2个方面,父节点调用子节点,子节点调用父节点,如当父节点向子节点发出写请求则要调用子节点的写操作,当子节点写操作完毕后,会调用父节点的写回调操作。父子节点的调用关系可用下图说明:
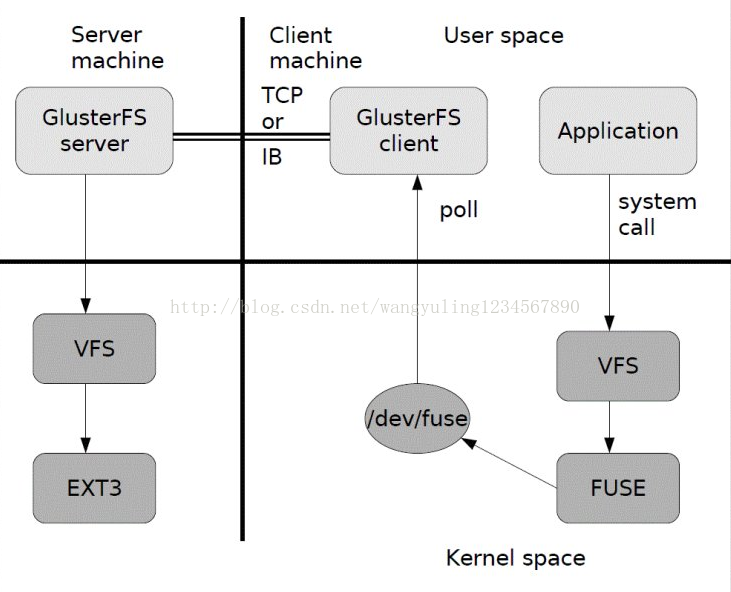
4. glusterfs总体工作流程
总体流程例如以下图所看到的:
1) 首先是在client, 用户通过glusterfs的mount point 来读写数据,对于用户来说,集群系统的存在对用户是全然透明的,用户感觉不到是操作本地系统还是远端的集群系统。
2) 用户的这个操作被递交给 本地linux系统的VFS来处理。
3) VFS 将数据递交给FUSE 内核文件系统:在启动glusterfs客户端曾经,须要想系统注冊一个实际的文件系统FUSE,如上图所看到的,该文件系统与ext3在同一个层次上面,ext3 是对实际的磁盘进行处理, 而fuse文件系统则是将数据通过/dev/fuse 这个设备文件递交给了glusterfsclient端。所以, 我们能够将 fuse文件系统理解为一个代理。
4) 数据被fuse 递交给Glusterfs client 后,client 对数据进行一些指定的处理(所谓的指定,是依照client配置文件据来进行的一系列处理
5. 主要模块介绍
Gluterfs总体採用堆栈式架构,模仿的函数调用栈,各个功能模块耦合度低,且非常多模块可自由结合形成不同的功能。以下主要介绍一下Glusterfs的主要模块:
5.1 DHT模块
该xlator主要实现了文件的哈希分布,将0到2的32次方依据子卷的个数平均划分若干个区间,文件到达DHT时,会依据文件名称计算所得的哈希值所在的区间,来决定该文件落在哪个子卷上。当中各个子卷的哈希区间记录在父文件夹的扩展属性中。此外,该模块还实现了数据迁移和扩容功能。
5.2 AFR模块
该xlator主要实现了文件级别的镜像冗余功能,类似raid1功能,只是不是块级别的。数据到达AFR时,会将ChangeLog加1,然后写数据,待所有子卷所有写成功后,再将ChangeLog减1。若须要修复时,依据ChangeLog推断哪个是source卷。实际的修复流程很复杂,包含meta,entry等。冗余卷没有主从之分,不论什么一个子卷都能够保证上层的读写请求,可在不影响上层应用的情况下运行修复功能。
5.3 Stripe模块
该xlator主要实现了文件的写条带,即文件到达Stripe时,会将文件按固定大小的条带写入各个子卷,类似raid0功能。在高版本号中,有两种模式:写空洞文件模式和聚合模式。该模块原理和实现都较DHT和AFR模块简单,且代码量较少,在此不再赘述。
—— —— 以上内容整理自互联网